www.jagostat.com
www.jagostat.com
Website Belajar Matematika & Statistika
Website Belajar Matematika & Statistika
Cari artikel...
Tutorial R
Tutorial R

Tutorial R » Visualisasi Data › Membuat Box Plot dalam Pemrograman R
Box Plot
Membuat Box Plot dalam Pemrograman R
Box plot sangat berguna untuk melihat distribusi data, ukuran pemusatan seperti median, kuantil, serta outlier atau pencilan. Di sini kita akan belajar cara membuat box plot menggunakan fungsi boxplot() dan package ggplot2.
Box plot sangat berguna untuk melihat distribusi data, ukuran pemusatan seperti median, kuantil, serta outlier/pencilan. Gambar di bawah menjelaskan bagian-bagian dari boxplot serta interpretasinya.
Di sini kita akan belajar cara membuat box plot menggunakan fungsi dasar (base function) dalam R yakni boxplot(). Selain itu, karena package ggplot2 banyak digunakan terutama untuk memvisualisasikan data, maka kita juga akan belajar cara membuat box plot menggunakan package ggplot2.
Fungsi boxplot(x) pada R akan memberikan hasil berupa 1 box plot jika x adalah vektor dan box plot per kolom jika x adalah sebuah data.frame.
Sebagai contoh, kita akan gunakan dataset bawaan R yaitu dataset state.
## Data ##
data(state)
head(state.x77)
Population Income Illiteracy Life Exp Murder HS Grad Frost
Alabama 3615 3624 2.1 69.05 15.1 41.3 20
Alaska 365 6315 1.5 69.31 11.3 66.7 152
Arizona 2212 4530 1.8 70.55 7.8 58.1 15
Arkansas 2110 3378 1.9 70.66 10.1 39.9 65
California 21198 5114 1.1 71.71 10.3 62.6 20
Colorado 2541 4884 0.7 72.06 6.8 63.9 166
Area
Alabama 50708
Alaska 566432
Arizona 113417
Arkansas 51945
California 156361
Colorado 103766
state.x77 <- data.frame(state.x77)
## Boxplot ##
par(mfrow=c(1,2))
boxplot(state.x77$Murder, xlab="Murder Rate", ylab="Rate")
boxplot(state.x77[1:3], xlab="Variable")

Terlihat pada box plot khusus untuk murder rate, median dari tingkat pembunuhan adalah sekitar 7, sedangkan Q1 dan Q3 adalah masing-masing sekitar 4 dan 11. Sedangkan box plot kedua yang merupakan box plot untuk tiga variabel yakni population, income, dan illiteracy tidak dapat dilakukan interpretasi.
Hal ini dikarenakan perbedaan satuan dari masing-masing variabel yang membuat mereka tidak dapat dibandingkan dalam satu boxplot seperti itu.
Kegunaan fungsi boxplot() untuk input matriks adalah ketika kita ingin membandingkan sebuah ukuran/satuan yang sama pada beberapa grup atau kelompok tertentu.
Sebagai ilustrasi, berikut adalah hasil lomba lari 100m dari 20 pelari yang berasal dari dua klub atletik A dan B. Maka kita dapat menggambarkan boxplot sebagai berikut:
## Input data
A <- c(12.9, 13.5, 12.8, 13.6, 17.2, 13.2, 12.6, 15.3, 14.4, 11.3)
B <- c(14.7, 15.6, 15.0, 15.2, 16.8, 20.0, 12.0, 15.9, 16.0, 13.1)
## digabung dalam bentuk matriks
dt <- cbind(A,B)
boxplot(dt, xlab="grup", ylab="waktu (detik)")
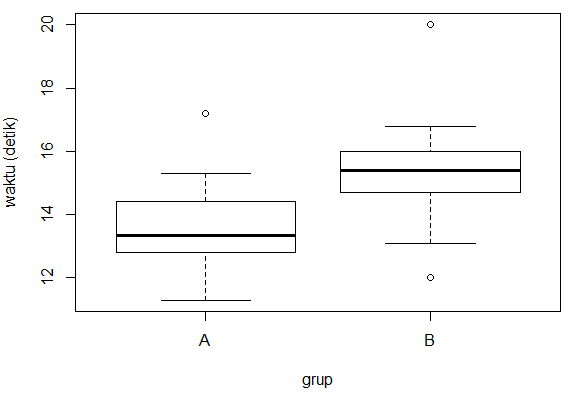
Dari hasil visualisasi terlihat bahwa secara umum pelari dari grup A lebih cepat dibandingkan grup B. Terdapat satu pelari dari masing-masing grup yang sangat lambat dibandingkan rekan lainnya.
Jika kita memiliki variabel atau kolom yang merupakan kategorik (bertipe factor), maka kita dapat menghasilkan boxplot dari masing-masing kategori tersebut.
Karena pada data state.x77 tidak terdapat variabel berjenis kategorik, maka sebagai ilustrasi kita buat variabel kategorik baru yang merupakan pengelompokan negara bagian berdasarkan income-nya menjadi tiga kelompok yakni "low" ( < 4000 ), "medium" ( 4000-8000 ), dan "high" ( > 4800 ). Variabel ini diberi nama incomeCode.
## Boxplot untuk beberapa grup ##
## Re-code dari income dan dimasukkan ke dalam dataset
## sebagai variabel baru
state.x77$incomeCode <- cut(state.x77$Income,
breaks = c(-Inf, 4000,4800,Inf),
labels = c("low", "medium","high"))
## Jika x adalah variabel berjenis factor, maka secara
## otomatis akan membentuk boxplot
plot(state.x77$incomeCode, state.x77$Illiteracy)
Output:
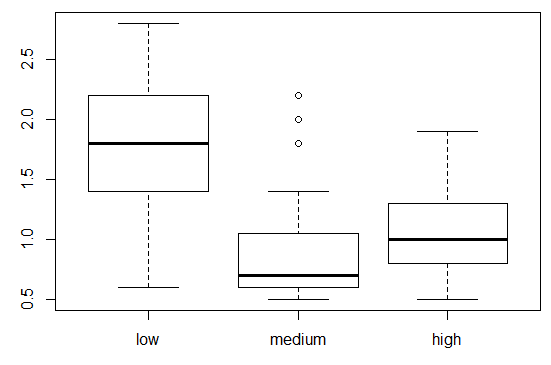
Terlihat bahwa median angka buta huruf pada negara bagian berpendapatan rendah jauh lebih tinggi dibandingkan negara-negara di dua grup lainnya. Yang menarik adalah grup negara bagian dengan pendapatan/income medium memiliki median angka buta huruf lebih kecil dibandingkan dengan grup pendapatan tinggi.
Artikel Terkait
Step out of the history that is holding you back. Step into the new story you are willing to create.
Oprah Winfrey