
www.jagostat.com
www.jagostat.com
Website Belajar Matematika & Statistika
Website Belajar Matematika & Statistika
Cari artikel...
ANALISIS REGRESI
Analisis Regresi
Regresi Linear Sederhana
Regresi Linear Berganda
Analisis Regresi » Regresi Linear Sederhana › Pendugaan Interval Parameter Model Regresi
Analisis Regresi
Pendugaan Interval Parameter Model Regresi
Pendugaan interval adalah pendugaan nilai parameter populasi dalam selang atau interval tertentu yang dibatasi oleh batas bawah dan batas atas estimasi.
Pada artikel sebelumnya kita telah membahas cara mencari estimator atau penduga titik bagi koefisien regresi dengan menggunakan metode kuadrat terkecil (ordinary least square) dan metode maksimum likelihood (maximum likelihood method), yang mana dari kedua metode tersebut memberikan hasil yang sama.
Namun, kerap kali yang kita inginkan bukanlah pendugaan titik melainkan pendugaan selang atau interval. Oleh karena itu, kita akan teruskan pembahasan terkait cara memperoleh penduga atau taksiran selang bagi parameter model regresi.
Pendugaan interval adalah pendugaan nilai parameter populasi dalam nilai selang atau dalam interval tertentu. Dalam pendugaan interval, nilai estimasinya terletak dalam interval atau selang tertentu yang dibatasi oleh batas bawah dan batas atas estimasi.
Supaya lebih jelas, perhatikanlah model regresi dari data sampel dengan satu variabel bebas berikut:
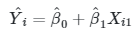 |
(1) |
Pada tulisan sebelumnya, kita telah berhasil mencari \(\hat{β}_0\) dan \(\hat{β}_1\), yaitu:
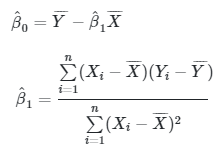 |
(2) |
dan telah kita ketahui bahwa \(\hat{β}_0\) dan \(\hat{β}_1\) adalah berdistribusi normal. Oleh karena itu, variabel \(Z\) berikut:
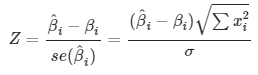 |
(3) |
akan berdistribusi normal standar yakni mempunyai rata-rata nol dan varians 1.
Penyebut dalam sampel acak \(Z\) di atas adalah standar deviasi populasi yang nilainya jarang diketahui, sehingga bisa digantikan dengan estimator yang tak bias (unbiased) \(\hat{σ}\). Jika kita menggantikan \(σ\) dengan \(\hat{σ}\), maka persamaan di atas akan menjadi:
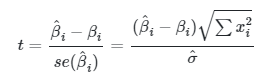 |
(4) |
Sampel acak \(t\) di atas akan mengikuti distribusi student-t dengan derajat bebas \(n – 2\). Oleh karena itu, daripada menggunakan distribusi normal, kita bisa menggunakan distribusi \(t\) untuk membangun selang kepercayaan bagi \(β_i\) sebagai berikut:
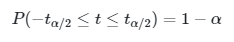 |
(5) |
di mana nilai \(t\) di tengah pertidaksamaan adalah nilai \(t\) yang diperoleh dari persaman (4), dan \(t_{α/2}\) merupakan nilai variabel \(t\) yang diperoleh dari tabel nilai kritis distribusi \(t\) dengan tingkat signifikansi \(α/2\) dan \(n-2\) derajat bebas. Dengan mensubstitusikan persamaan (4) ke dalam persamaan (5) diperoleh
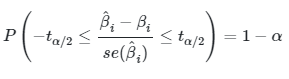 |
(6) |
yang mana setelah disederhanakan menjadi
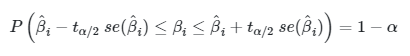 |
(7) |
Persamaan (7) memberikan selang kepercayaan \(100(1-α)\) persen bagi \(β_i\), yang mana bisa dituliskan secara ringkas dengan \( \hat{β}_i \pm t_{α/2} \ se(\hat{β}_i) \). Dengan demikian, selang kepercayaan bagi \(β_0\) adalah:
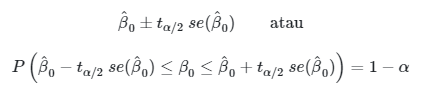
dan selang kepercayaan bagi \(β_1\) adalah
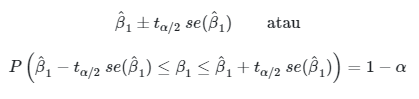
Persamaan di atas bisa dibaca sebagai berikut: \(100(1-α)\)% dari seluruh kemungkinan estimasi selang yang dapat dibuat dari seluruh kemungkinan sampel akan mencakup nilai parameter \(β_0\) atau \(β_1\). Estimasi selang yang kita peroleh adalah salah satu dari seluruh kemungkinan estimasi selang tersebut. Dengan demikian, kita mempunyai keyakinan \(100(1-α)\)% bahwa estimasi selang yang kita peroleh adalah salah satu yang mencakup atau mengandung nilai \(β_0\) atau \(β_1\).
Artikel Terkait
Cara terbaik untuk memperkirakan masa depan adalah dengan menciptakannya.
Abraham Lincoln