www.jagostat.com
www.jagostat.com
Website Belajar Matematika & Statistika
Website Belajar Matematika & Statistika
Cari artikel...
Machine Learning
Machine Learning

Machine Learning » Pendahuluan › Beberapa Cara Mengatasi Outlier (Pencilan) dalam Data Statistik
Beberapa Cara Mengatasi Outlier (Pencilan) dalam Data Statistik
Adanya outlier dalam data statistik perlu diatasi atau ditangani sebelum melakukan proses analisis data. Pada kesempatan ini, kita akan membahas cara-cara penanganan outlier.
Outline Artikel:
- Apakah Outlier Harus Selalu Ditangani?
- Menggunakan Analisis Statistik yang Bisa Menangani Outliers
- Mengatasi Outlier dengan Menghapus Data Outlier
- Mengganti Nilai Outlier dengan Melakukan Imputasi Data
Oleh Iman Jihad Fadillah · Statistisi
6 Januari 2023
Pada tulisan sebelumnya, kita sudah membahas apa itu outlier dalam data statistik dan bagaimana mengidentifikasi outlier. Setelah memahami kedua pembahasan tersebut, langkah selanjutnya adalah apa yang harus kita lakukan terhadap data outlier tersebut? Keberadaan outlier perlu dihindari/ditangani sebelum melakukan proses analisis data. Pada kesempatan ini, kita akan membahas cara-cara penanganan outlier.
Apakah Outlier Harus Selalu Ditangani?
Seperti yang sudah dijelaskan pada tulisan sebelumnya, bahwa adanya outlier pada data dapat menyebabkan analisis-analisis yang menggunakan metode statistik standar menjadi bias. Namun, apakah semua outlier itu perlu ditangani?
Sebelum menjawabnya, mari kita bahas secara singkat terkait eksplorasi data. Secara umum, salah satu bagian terpenting sebelum melakukan analisis data adalah melakukan ekplorasi data. Dengan melakukan eksplorasi terhadap data, kita dapat memperoleh informasi terkait distribusi data, struktur dan bentuk data, serta adanya data outlier, missing, noisy, ataupun data yang tidak konsisten antara yang satu dengan lainnya.
Setelah selesai melakukan ekplorasi data, kita bisa menentukan apakah data yang dimiliki sudah sesuai dengan analisis yang akan dilakukan, atau perlu dilakukan cleaning pada data tersebut. Dengan begitu, setelah ekplorasi data selesai dan kita mengenal dataset yang akan dianalisis, kita bisa menentukan apa yang akan dilakukan seperti metode analisis apa yang akan dipakai atau penanganan-penanganan lainnya yang sekiranya diperlukan.
Secara umum, outlier jelas harus ditangani, karena memang membuat analisis menjadi bias. Contoh dari bias tersebut sudah kita contohkan pada tulisan sebelumnya pada perhitungan rata-rata. Namun pada kasus tertentu, outlier bisa saja menunjukkan sebuah fenomena tertentu, sehingga jika data outlier itu dibuang, maka akan menghilangkan informasi penting yang terkandung dalam data. Sebagai contoh, perhatikan data pertumbuhan ekonomi Indonesia berikut.
Contoh 1:
Data series pertumbuhan ekonomi Indonesia tahun 2010-2021
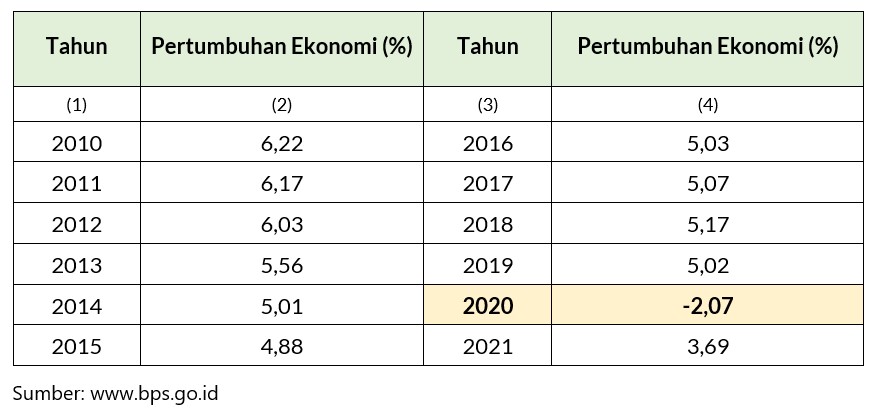
Pada series data tersebut, data pertumbuhan ekonomi Indonesia tahun 2020 dapat digolongkan sebagai outlier, tetapi outlier ini memiliki sebuah informasi penting, yaitu tahun terjadinya Pandemi Covid-19, yang mana ada kejadian dan fenomena di tahun tersebut. Jika outlier tersebut dibuang, maka informasi yang terkandung dalam data tersebut tentunya juga akan ikut menghilang.
Contoh di atas menunjukkan bahwa data outlier tidak selalu harus dibuang. Lantas bagaimana cara mengatasi data outlier yang tidak dibuang atau tetap dipertahankan dalam data yang akan kita analisis? Salah satu caranya adalah menggunakan metode analisis statistik yang bisa mengatasi outlier.
Menggunakan Analisis Statistik yang Bisa Menangani Outliers
Sebagian jenis outlier dapat ditangani dengan tidak menghapus outlier tersebut. Untuk mengatasi outlier tanpa menghapusnya, kita dapat memanfaatkan metode analisis statistik lain yang tidak terpengaruh, tidak sensitif, atau bisa mengatasi outlier.
Sebagai contoh, kita akan gunakan data tinggi badan pada tulisan sebelumnya.
Contoh 2:
Diketahui suatu kelompok data yang terdiri dari 10 siswa, 9 siswa di antaranya memiliki tinggi badan normal berkisar 165-175 cm dan 1 siswa dengan tinggi badan outlier yang memiliki tinggi badan 110 cm. Adapun tinggi masing-masing siswa tersebut sebagai berikut:
110, 165, 174, 171, 174, 167, 175, 166, 170, 165
Dari data di atas, diperoleh informasi rata-rata tinggi badan 9 siswa dengan tinggi badan normal adalah 169,67 cm, sedangkan rata-rata tinggi badan ke 10 siswa adalah 163,70 cm. Rata-rata sebesar 163,70 cm tentu tidak mencerminkan data tinggi badan dari 10 siswa tersebut karena terdapat tinggi badan siswa yang outlier.
Untuk mengatasi ini, kita dapat menggunakan metode statistik lain yang tidak sensitif terhadap outlier, misalnya nilai Median/Nilai Tengah. Median dari 9 siswa dengan tinggi badan normal adalah 170 cm, sedangkan median dari tinggi badan 10 siswa yaitu 168,5 cm. Perhatikan bahwa nilai median ke 9 siswa maupun 10 siswa (termasuk outlier) tidak berbeda jauh, dan masih berada di dalam rentang 165-175 cm. Hasil tersebut merupakan salah satu contoh penanganan outlier untuk permasalahan ukuran pemusatan data.
Beberapa metode analisis statistik lain yang bisa digunakan untuk mengatasi permasalahan outlier antara lain, Regresi Robust untuk mengatasi Regresi Linier, Uji U Mannn Whitney, Uji McNemar, Uji Wilcoxon untuk menangani uji T, atau Uji Kruskal-Wallis untuk mengatasi ANOVA satu arah. Adapun penjelasan dan contoh untuk tiap-tiap metode sudah dibahas pada pembahasan-pembahasan sebelumnya di website ini.
Menghapus Outlier
Setelah memahami dua poin pembahasan di atas, sekarang kita melangkah ke pembahasan berikutnya, yaitu menangani outlier dengan cara menghapus data outlier tersebut. Poin ini sengaja ditempatkan setelah dua penjelasan sebelumnya, agar kita tidak mudah untuk menghapus data, walaupun data tersebut adalah sebuah outlier. Hal ini untuk menghindari hilangnya informasi penting yang melekat pada data tersebut jika data outliernya dihapus.
Selain itu, menghapus data akan membuat jumlah amatan yang diamati menjadi berkurang. Mengatasi outlier dengan menghapus data outlier sebaiknya menjadi pilihan terakhir karena sekarang sudah tersedia alternatif-alternatif metode yang bisa digunakan dengan menyertakan data outlier.
Contoh 3:
Seperti data pada Contoh 2, dari 10 siswa, ada 1 siswa yang memilki tinggi badan outlier. Rata-rata tinggi badan ke 10 siswa adalah 163,70 cm, padahal sebagian besar populasi (selain outlier) memiliki tinggi badan 165-175 cm.
Dengan menghapus 1 siswa tersebut dari kelompok data, maka data akan kembali normal, dan nilai rata-ratanya menjadi 169,67 cm. Nilai rata-rata ini sesuai dengan gambaran populasi yang ada. Namun, konsekuensinya adalah data yang awalnya berjumlah 10 siswa, sekarang hanya menjadi 9 siswa.
Mengganti Nilai Outlier dengan Melakukan Imputasi Data
Ada alternatif lain yang bisa digunakan untuk mengatasi outlier, salah satunya adalah imputasi data. Singkatnya, imputasi data adalah mengganti nilai hilang (missing value) menggunakan nilai lain dari hasil imputasi data. Jadi, nilai data yang mengandung outlier akan dihapus, kemudian digantikan menggunakan nilai lain.
Metode ini, salah satunya untuk mengatasi dampak dari menghapus unit amatan yang merupakan outlier agar tidak mengurangi jumlah amatan yang diteliti. Salah satu imputasi sederhana adalah mean imputation. Mari kita contohkan penggunaan mean imputation atau imputasi rata-rata berikut ini.
Contoh 4:
Seperti data pada Contoh 2, berikut adalah tinggi badan (cm) ke 10 siswa:
110, 165, 174, 171, 174, 167, 175, 166, 170, 165
Berdasarkan hasil identifikasi diperoleh 1 data outlier, sehingga dengan menghapus data outlier tersebut, maka tinggi badan (cm) kelompok data menjadi:
X, 165, 174, 171, 174, 167, 175, 166, 170, 165
Selanjutnya, nilai X akan diimputasi menggunakan rata-rata dari sisa nilai yang ada (rata-rata tinggi badan 9 siswa) yaitu sebesar 169.67 cm. Sehingga diperoleh kelompok data baru dengan nilai sebagai berikut:
169.67, 165, 174, 171, 174, 167, 175, 166, 170, 165
Penggunaan metode ini tentunya memiliki kelebihan dan kekurangan. Pembahasan lebih detail terkait imputasi data akan dibahas pada kesempatan lain.
Editor: Tju Ji Long · Statistisi
Artikel Terkait
A pessimist sees the difficulty in every opportunity; an optimist sees the opportunity in every difficulty.
Winston Churchill